Five days, one train ride, one digitizer: a single week, start to finish
I went to Toronto for the TMLS hackathon with Mo and Luca. We built a document digitizer Monday to Friday, demoed Friday, took the train Saturday and used the ride to wire the good parts into production. By Sunday it was live, tested top to bottom, and demo-able.
The five day frame
I went to Toronto for the TMLS hackathon last week. Monday to Friday, five days, one product. Team of three: myself, Luca and Mo. Thursday was the cutoff for development. Friday was the demo for judges from the FGF bakery team, a 5 billion dollar business with almost 100 engineers. The mission was wider than the prize: I wanted to see what the current landscape actually looks like for digitizing documents. Not what the marketing pages claim. What the models can do today when you point them at the messy real world.
I came at this with scar tissue. At Wisk I was CTO and we dealt with invoices from tens of thousands of different suppliers. I know exactly where these systems crack: the handwritten note in the corner, the supplier who faxes you their invoice, the multilingual line item, the rotated scan from a phone camera. So when I joined the hackathon, I had a specific test in mind for whatever we built.
Mo brought significant OCR experience. He is currently building a product around searchable document datasets, so he had walked into every wall this space has. Luca is newer to software but very enthusiastic, and he ended up building UI components that survived the rewrite intact.
What we tried in the hackathon week
We threw the lab at it. Mistral. Mixtral. ChatGPT-5.4. Qwen variants. Azure Document Intelligence. We compared them on the same handwritten invoice and watched where each one fell over. We tried different pipelines for bbox extraction, different strategies for orientation detection, different prompt structures for field extraction. We looked at the commercial competitors honestly: what is genuinely hard, what is commodity now, what is worth building yourself.
By Friday we had a working demo. The judges saw it. The week ended.
The train ride home
Saturday I took the train from Toronto to Montreal. Five hours. Internet was spotty most of the way, which actually helped. I had my laptop open the whole way and I used the ride to do the part most hackathon projects skip: take only the good ideas, throw away the hackathon code entirely, and move them into a repo that was already production-shaped.
Important caveat. I was not building the production scaffolding on the train. I already had that. Across my other projects I already have:
- Terraform for the Azure resources
- A GitHub Actions deploy pipeline (build images, push to ACR, roll Container Apps)
- A Postgres + Key Vault pattern I reuse
- A Python (FastAPI) backend skeleton with a tested pipeline shape
- A Next.js frontend skeleton with the design system from styleguide.ideaplaces.com
So the train ride was not "write the CI/CD." It was "take the hackathon code, decide what survives, drop the rest, and wire the survivors into the existing skeleton." That is a much smaller, much cleaner unit of work than building from zero, and it is exactly the kind of work an offline train ride is good for.
By the time I rolled into Montreal: end to end working, every pipeline step unit and integration tested, the live URL responding. Sunday I added the demo gallery, processed a stack of varied real-world documents through the pipeline to stress-test it, and made it actually demo-able. The result is at digitizer.ideaplaces.com.
What the hackathon actually taught me
The technical lesson worth keeping: hybrid wins. VLMs bridge the visual layer and classical machine learning, but they are not a replacement for classical software. The best pipelines combine them deliberately.
Concrete example from our pipeline. For document rotation we run Tesseract OSD first. It is fast, classical, cheap. If it returns a high-confidence guess, we use it. If the confidence is below threshold (which it often is for handwritten pages), we fall back to a VLM that judges orientation by looking at the rendered image. The classical tool handles the 80% case for cents. The VLM handles the long tail.
Same for bboxes. The VLM returns approximate bboxes for every field, but they drift by 5 to 10 percent because the model is not optimized for pixel-accurate localization. So we run a second pass: a focused locator call that takes the extracted text values and snaps the bboxes tightly to the page. Each tool does what it is good at.
This pattern is going to become more important, not less, as the model landscape matures. Picking one technology and committing to it monogamously is the wrong shape. The right shape is: a pipeline where each step uses the cheapest tool that solves it correctly, with one fallback tier for when the cheap tool gives up.
A footnote: a kid's letter to Santa Claus
Somewhere on Sunday, while I was reaching into my own phone camera roll for edge cases (phone photos are the genuinely ugly case: angle, glare, EXIF orientation, partial crops), I found a small folder of photos I had taken of my kids' handwritten letters to Santa. Three of them, across three different years. Cursive French ("Cher Père Noël" at the top), no labels, no fields, just prose.
I uploaded one. It returned clean structured JSON. The greeting field. The sender field with the kid's name. The age field. The full wish list as the body.
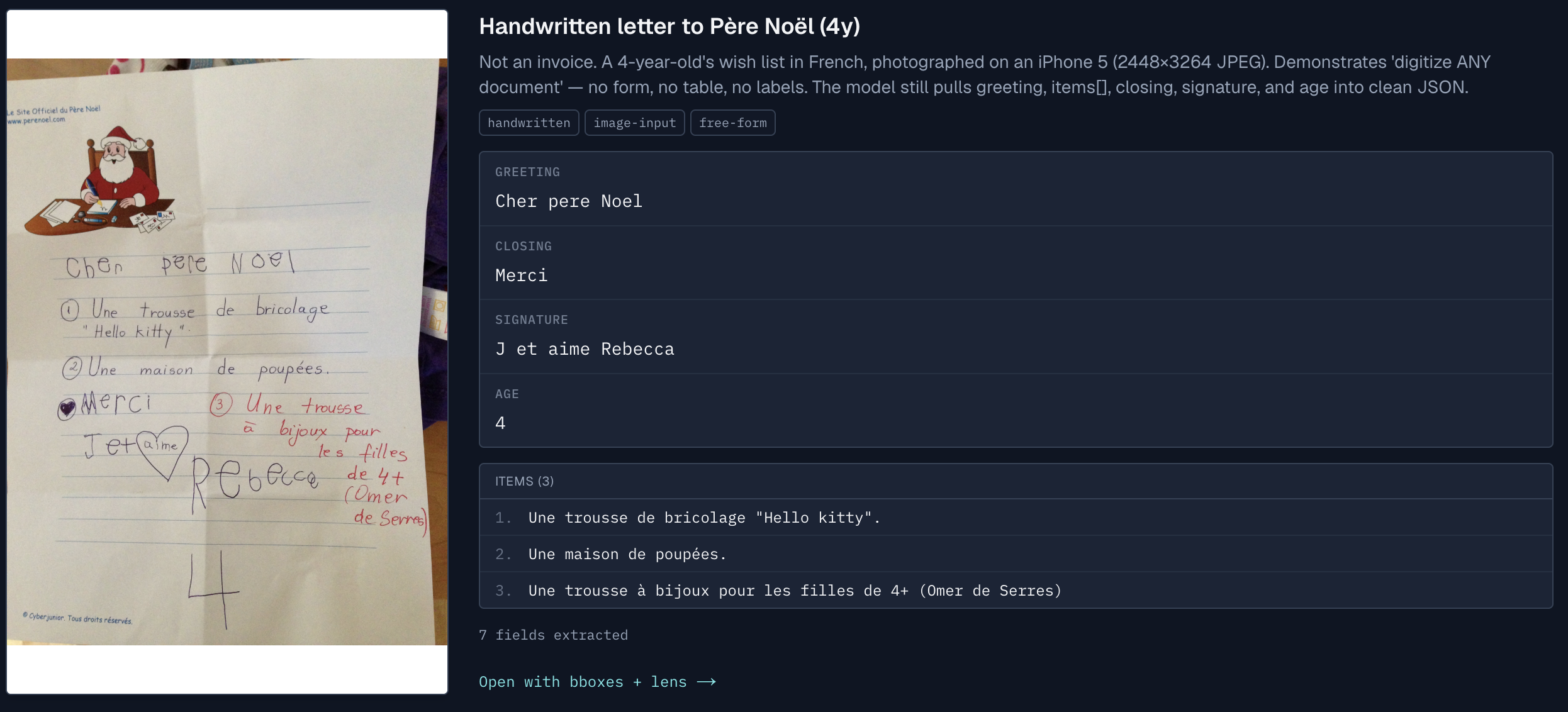
That is when I started laughing. Because if you think about it, who actually receives millions of unstructured handwritten documents every December? One person. He gets letters from kids all over the world, in dozens of languages, all written by hand, none of them following any schema. And right now somebody has to read them and figure out which kid gets the toy bus and which one gets the robot dog.
So maybe our highest-volume Q4 "customer" is Santa Claus. Not to replace him. To free him from the OCR. An agent reads every letter, structures the wishes, dispatches the elves making the toys. Santa stays Santa. The dispatch becomes agentic.
I am only half joking. The serious version: every industry that did not move fast enough is still paper first. Old invoices, faxed referrals, handwritten medical forms, archival material, customs paperwork. Each one of those is one good digitization layer away from being usable by AI agents. That is where this goes next.
Where this lives now
It is at digitizer.ideaplaces.com. API key login. A few thousand documents per day at current capacity, scaling to tens of thousands once we add queueing (the architecture is ready for it, we just have not pulled that lever yet). Every layer is tested. The repo is clean. If somebody on your team has a stack of PDFs or scans that have resisted automation, point it at the URL.
The Toronto week
The hackathon was one of three things I did with the week. I also went to a CTO meetup, and signed up for a second hackathon I will write about separately. Toronto created a space for me to play with technology rather than just talk about it. That distinction matters more than it sounds. A lot of the current AI conversation is theoretical. You read papers, you watch demos, you have opinions on Twitter. But none of that proves the point as clearly as: I had an idea on Monday morning, by Saturday night it was a live URL with an API.
The speed from idea to shipping product is the other thing the week made tangible. The tooling has compressed so much of what used to be the slow part. The slow part now is taste. Knowing which models to combine, which corners to cut, which to over-engineer. That is the skill the next decade rewards.
If you are working on something in document AI, or you have a use case where the current OCR stack is failing you, send me your worst document. Honestly. The harder the better. That is how the next iteration of this thing gets built.
Try it: digitizer.ideaplaces.com